Câu chuyện về OCR và sức mạnh ngầm của một công nghệ xử lý "big data"
Trong thế giới số có một thuật ngữ gọi là "Dark data" - "Dark data" là dữ liệu không có cấu trúc, chưa thể sử dụng được nếu không qua xử lý, phân tích, sắp xếp. Nếu data tăng lên với cấp số nhân thì trong đó phần được cho là "dark data" tăng lên theo cấp số mũ. Điều này đòi hỏi con người phải sẵn sàng các giải pháp xử lý dữ liệu lớn và siêu lớn. Vai trò của dữ liệu là đặc biệt quan trọng, nhưng việc khai thác, tối ưu dữ liệu trở thành tài sản có giá trị lại không hề đơn giản.
Trong khoảng 3 năm gần đây, giải pháp số hóa văn bản OCR trở nên hấp dẫn với nhiều doanh nghiệp bởi sức mạnh xử lý dữ liệu của nó. Nhưng ít ai biết, từ những năm đầu của thế kỷ XX, nhà vật lý Emanuel Goldberg đã phát triển một máy đọc các ký tự và chuyển đổi chúng thành mã điện báo tiêu chuẩn được gọi là "máy tính thống kê" để tìm kiếm số lưu trữ trong vi phim (microfilm) bằng cách sử dụng một hệ thống nhận diện mã quang học.
Năm 1931, ông được cấp bằng sáng chế của Hoa Kỳ số 1,838,389 cho phát minh của mình và sau đó đã được mua lại bởi IBM. Cùng thời, Edmund Fournier d'Albe đã phát triển Optophone, một máy quét cầm tay khi di chuyển trên một trang in, tạo ra các âm tương ứng với các chữ cái hoặc ký tự cụ thể.
Đây chính là nền móng đầu tiên của việc tự động hóa lưu trữ hồ sơ, mang "dữ liệu tối" ra ánh sáng bằng cách tạo ra các dữ liệu có cấu trúc (bảng SQL) từ thông tin phi cấu trúc (văn bản, bảng biểu, hình ảnh...) và tích hợp dữ liệu đó với cơ sở dữ liệu có cấu trúc hiện có. IBM đã nhanh chóng mua lại bằng sáng chế của Emanuel và tiếp tục nghiên cứu, phát triển. Cho đến năm 2002, việc có thể sử dụng OCR ngay trên điện thoại di động và máy tính để bàn thông qua điện toán đám mây được coi là một bước ngoặt.
Tại Việt Nam, mặc dù OCR được tiếp cận sau nhưng đến nay đã đạt được những kết quả tương đương với thế giới trong việc xử lý ngôn ngữ tiếng Việt (các công ty công nghệ lớn trên thế giới thường tập trung xử lý ngôn ngữ tiếng Anh).
Năm 2020, theo quy định của Thông tư 23/2019/TT-NHNN, các dịch vụ ví điện tử, thanh toán trung gian phải xác thực tài khoản người dùng qua CMND, hay các quy định liên quan đến mở tài khoản của Ngân hàng Nhà nước là động lực thúc đẩy doanh nghiệp nhanh chóng ứng dụng OCR để trích xuất thông tin, tự động hóa quá trình nhập liệu và xét duyệt thông tin. Trước nhu cầu lớn, thị trường mở rộng, chính sách của nhà nước thúc đẩy chuyển đổi số là động lực để Trung tâm không gian mạng Viettel đã tập trung nghiên cứu, đóng gói bộ giải pháp OCR trên cơ sở kết hợp các công nghệ:
- Công nghệ nhận dạng ký tự quang học (OCR) cho phép nhận dạng tài liệu dạng PDF, dạng ảnh, văn bản giấy…;
- Công nghệ xử lý ngôn ngữ tự nhiên (NLP) tự động hiệu chỉnh thông tin đảm bảo độ chính xác cao về mặt ngữ nghĩa
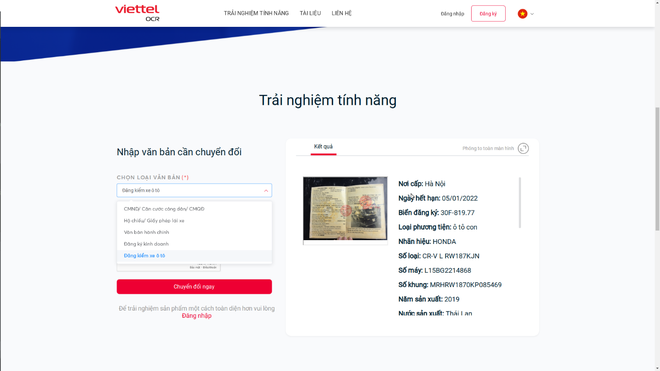
Sức mạnh của Viettel OCR còn đến từ công nghệ học sâu (Deep Learning) đem lại kết quả nhận dạng trên 99% đối với chữ in, trên 90% đối với chữ viết tay và lên tới 98% đối với việc trích xuất thông tin theo trường, vượt trội so với các nhà phát triển cùng lĩnh vực trên thị trường từ 4-5%.
Năm 2020 - cuộc dấn thân của Viettel OCR để giải quyết những case study cụ thể
Tháng 10/2020, trước đầu bài của Công ty Cổ phần Giao thông số Việt Nam (ePass) về việc triển khai mở tài khoản thu phí không dừng với tham vọng phủ rộng đến 4 triệu xe ô tô trong giai đoạn bùng nổ thị trường của dịch vụ này, Viettel OCR nhanh chóng đưa ra "lời giải" bằng việc xử lý quét tự động ~5000 bộ hồ sơ/ngày với độ chính xác lên tới 98%, áp dụng cho đa dạng các loại giấy tờ như: CMND, Bằng lái xe, Đăng ký xe, Đăng kiểm, Đăng ký kinh doanh... chuyển đổi thành dạng ký tự số có thể tìm kiếm, chỉnh sửa và lưu trữ dễ dàng. Có thể nói, cuộc "dấn thân" của OCR đóng góp phần vào tốc độ tăng trưởng thần tốc của ePass. Tính đến tháng 7/2020 đã có 8000000 tài khoản người dùng.
Với ngành tài chính ngân hàng, theo nghiên cứu của PricewaterhouseCoopers (PwC), trung bình, một tổ chức tài chính phải trả 20 USD để gửi một hồ sơ, và khoảng 120 USD để tìm một hồ sơ bị thiếu theo cách thủ công. Thế nhưng, với mô hình OCR được thiết kế và lắp đặt đúng cách, doanh nghiệp sẽ có nguồn dữ liệu "sạch" ngay từ đầu, dễ dàng chỉnh sửa và đồng bộ hóa.
Đặc biệt, dữ liệu được sắp xếp hệ thống hóa giúp dễ dàng quản lý và tái sử dụng trong kho dữ liệu lớn của doanh nghiệp, hỗ trợ hầu khắp các mẫu giấy tờ như: chứng minh nhân dân, hợp đồng, biên lai, mà còn là giấy vay tiền, báo cáo tài chính,… Tác động của công nghệ sẽ biến những quy trình từ rườm rà, phức tạp trở nên tối giản, tự động và chính xác. Viettel OCR dễ dàng tích hợp và triển khai trên các hệ thống như CMS, ERP, CRM… thông qua các API mở.
Piyush Gupta, CEO Ngân hàng DBS đã từng nói: "Tại DBS, chúng tôi hoạt động ít giống một ngân hàng mà như một công ty công nghệ hơn" - đây có lẽ là xu hướng có tính chất toàn cầu và đang dần hình thành tại Việt Nam.
Lan Hương - Trường Thịnh
Nguồn tin: dantri.com.vn
CEO Công nghệ NHNN Ngân hàng Ngân hàng Nhà nước OCR Việt Nam chính sách doanh nghiệp dịch vụ
Bài viết liên quan

Bấm để xem thêm ...
MARKETPLACE
NHÓM MUA TRỰC TUYẾN PHIÊN CHỢ TRỰC TUYẾN ĐẤU GIÁ TRỰC TUYẾN SEAONER NFT MALL SEAONER AI MALL SEAONER DATACENTER MALL SEAONER TOP TECH MALL MÁY BỘ VI TÍNH DỊCH VỤ IT & MORES ROSA PC MALL ROSA e-COMMERCE ĐỒ HỌA & LÀM PHIM MÁY VĂN PHÒNG MÁY CHIẾU PHIM 4K/8K LINH KIỆN VI TÍNH GAMING GEARS PHỤ KIỆN VI TÍNH CLB4U SDK PLATFORM LẬP TRÌNH WEB3 APP DỰ ÁN AI MÁY CHỦ DOANH NGHIỆP CLOUD SERVER & HOSTING DATACENTER TRANG THIẾT BỊ AI THIẾT BỊ HIỂN THỊ THÔNG MINH GAMES & PHÒNG GAME CHUYỂN ĐỔI SỐ THIẾT BỊ KỸ THUẬT SỐ THIẾT BỊ ÂM THANH ÁNH SÁNG SMARTHOME & SMART OFFICE CÀ PHÊ NHÀ HÀNG CARS & MORES BIKES & MORES THỜI TRANG & CUỘC SỐNG THỰC PHẨM ORGANIC BEER COFFEE TEA LOUNGE GLAMPING & CAMPING THỰC PHẨM TƯƠI SỐNG NỘI NGOẠI THẤT & KIẾN TRÚC DU LỊCH & CUỘC SỐNG THỰC PHẨM CHỨC NĂNG THIẾT BỊ GIA DỤNG ĐIỆN THOẠI & PHỤ KIỆN MẸ & BÉ THỦ CÔNG MỸ NGHỆ & MỸ THUẬT KẾT NỐI DOANH NGHIỆP SỬA CHỮA BẢO TRÌ & DỊCH VỤ TRANH ẢNH & NGHỆ THUẬT KẾ TOÁN & THUẾ & THÀNH LẬP DN NÔNG NGHIỆP THÔNG MINH NÔNG SẢN SÀN NÔNG NGHIỆP SIÊU THỊ THỰC PHẨM SẠCH THIẾT KẾ & IN ẤN THỰC PHẨM KHÔ & ĐÓNG GÓI THỦY HẢI SẢN THỦY HẢI SẢN & NUÔI TRỒNG TRẠM XĂNG VĂN PHÒNG PHẨM VỆ SINH CÔNG NGHIỆP & CHUYỂN NHÀ XÂY DỰNG & CẢI TẠO CÔNG TRÌNH XÂY DỰNG & VẬT LIỆU XÂY DỰNG
Thể loại giao dịch
Cần Bán Cần Mua Dịch vụ SaaS Affiliate Marketing Dịch vụ AIaaS Cho thuê Dịch vụ XaaS Dịch vụ PaaS Dịch Vụ Dịch vụ IaaS Tư vấn Đấu Giá Đấu Giá Trực Tuyến Đấu Thầu Ký Gửi Nhóm Mua Thi Công Trao Đổi Dịch Vụ Trao Đổi Sản Phẩm Xuất Nhập Khẩu Xúc Tiến Thương Mại